Claris Connect、Documents Utilityを触る(1)
Dates Utilityの機能は大きく2種類
- 画像やドキュメントファイルからのテキスト抽出
- データ形式のコンバート」の2つの役割
今回は画像やドキュメントファイルからのテキスト抽出について

Extract text from .pdf(pdfからテキストを抽出する)
- 指定したURLにあるpdfからテキストを取得
- パスワード付きのPDFにも対応
- 改行コード(¥n)のありなしを、指定できる
- 現在(2020/06/07)日本語の抜き出しは、文字化けする

- 文字コードはUTF-8で指定(これで合っているはず)
- 他の文字コードの選択肢でも、念のためトライしたが失敗

- 英語は問題なし
Extract text from .doc or .docx(docまたは.docxからテキストを抽出する)
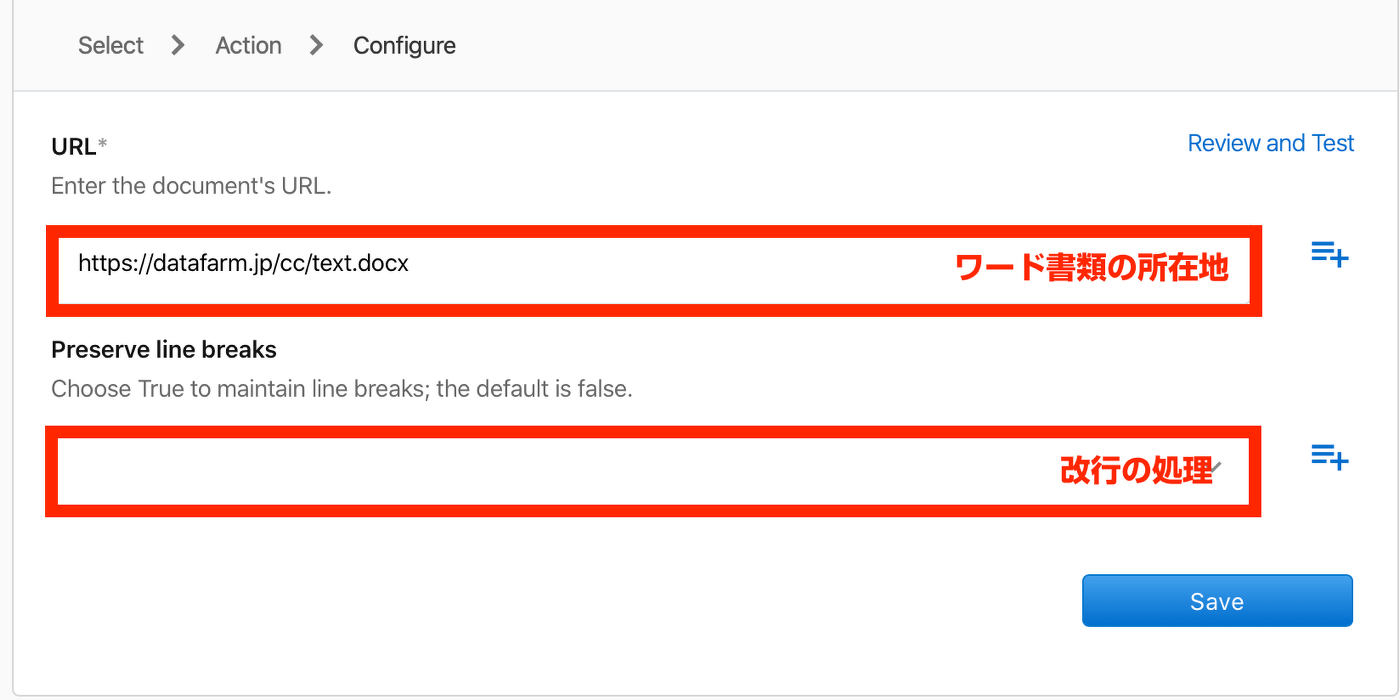
- 指定したURLにあるWord書類からテキストを取得
- 改行コード(¥n)のありなしを、指定できる

- 日本語も問題なし
Extract text from .png or .jpg(pngまたは.jpgからテキストを抽出する)
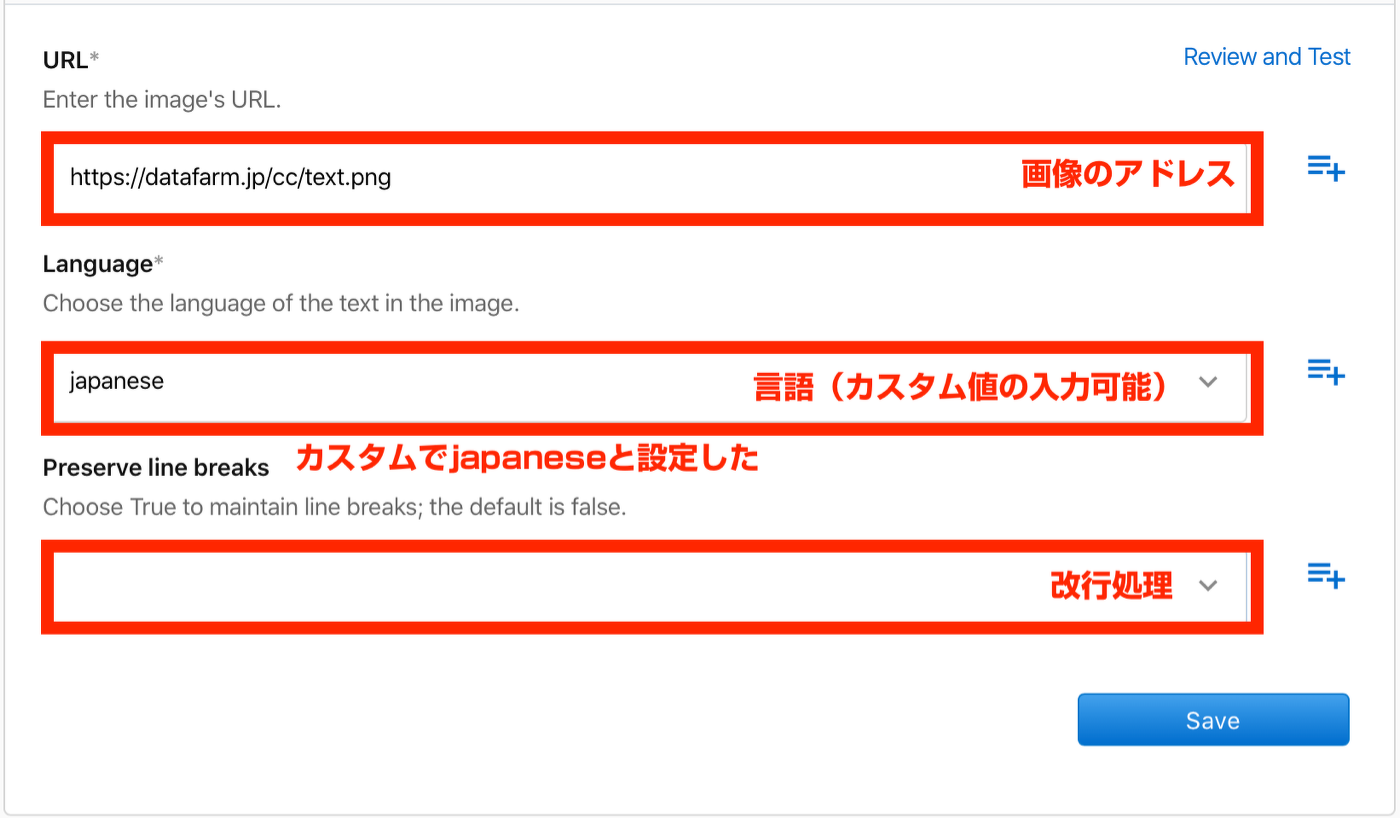
- 指定したURLにある画像からテキストを取得
- 画僧がどの言語かを指定する必要がある(カスタム値も入寮可能)
- 改行コード(¥n)のありなしを、指定できる
- 日本語の取得は失敗

- カスタム入力で言語を日本語(Japanese)に指定したが、404エラーで失敗

- 英語の場合は画像からテキストの抽出が可能
Extract text from .rtf(rtfからテキストを抽出する)
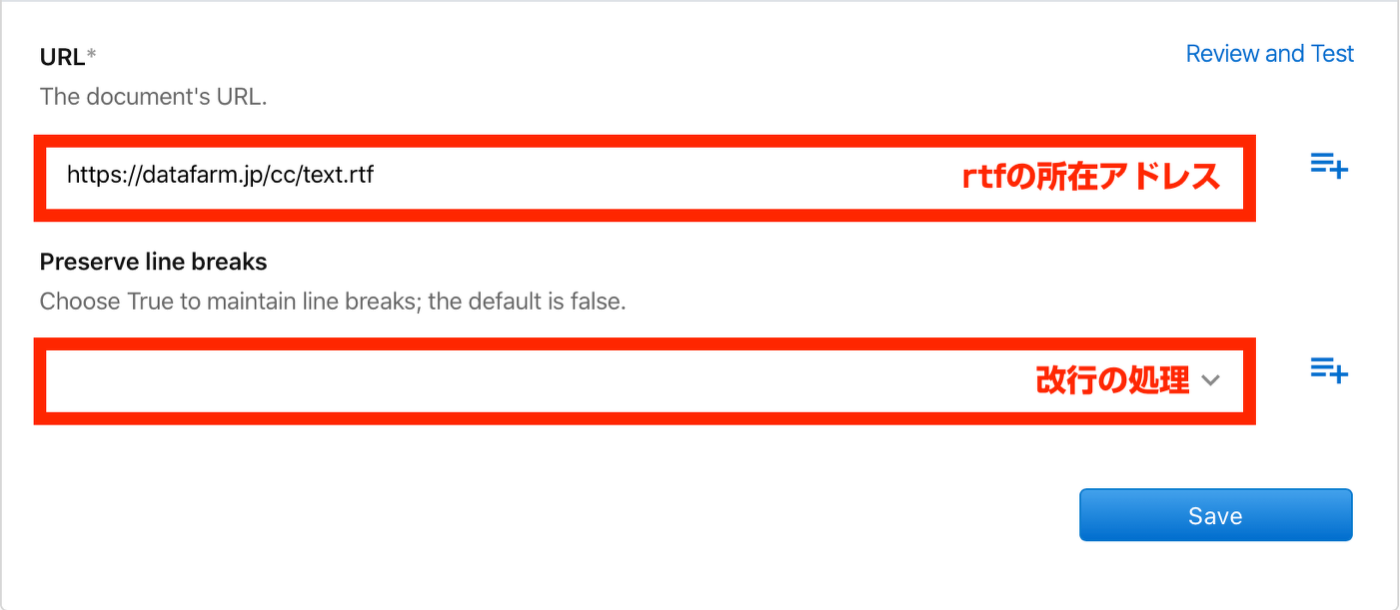
- 指定したURLにあるリッチテキスト書類からテキストを取得
- 改行コード(¥n)のありなしを、指定できる

- 日本語テキストも取得可能
使ってみた感想
- PDFや画像からテキストの抽出ができるのは、非常に面白い機能。
- 図表が入っている場合に、どれくらいの精度でテキストが抽出されるのかは気になる。
- 実際の使い所があるかどうかは、ちょっと悩むところもあるかもしれない(Word書類や、pdf書類のの内容をそのまま展開するケースは考えにくく、何かしらの処理が追加されてはじめてワークフローに活用できるのではないか)